문제 : https://leetcode.com/problems/successful-pairs-of-spells-and-potions/description/
spells와 potions이라는 길이가 각각 n과 m인 두 개의 양의 정수 배열이 주어집니다. 여기서 spells[i]는 i번째 주문의 강도를 나타내고, potions[j]는 j번째 물약의 강도를 나타냅니다. 그리고 주문과 물약의 강도를 곱한 값이 success 이상이면 성공적인 것으로 봅니다.
각 주문에 대해 성공적인 값을 이룰 수 있는 물약과 주문 pair 수를 나타내는 배열을 구하세요.
그리디 문제입니다.
먼저 spells와 potions를 정렬해야 하는데, 구하고자 하는 배열은 각 spell에 대한 값을 원하므로 spells는 해당 값의 인덱스를 같이 저장하는 배열을 만들어서 값을 기준으로 오름차순 정렬해줍니다. potions는 내림차순 정렬합니다.
문제의 예제 1번으로 한 번 해보겠습니다.
spells = [5, 1, 3]
potions = [1, 2, 3, 4, 5]
success = 7
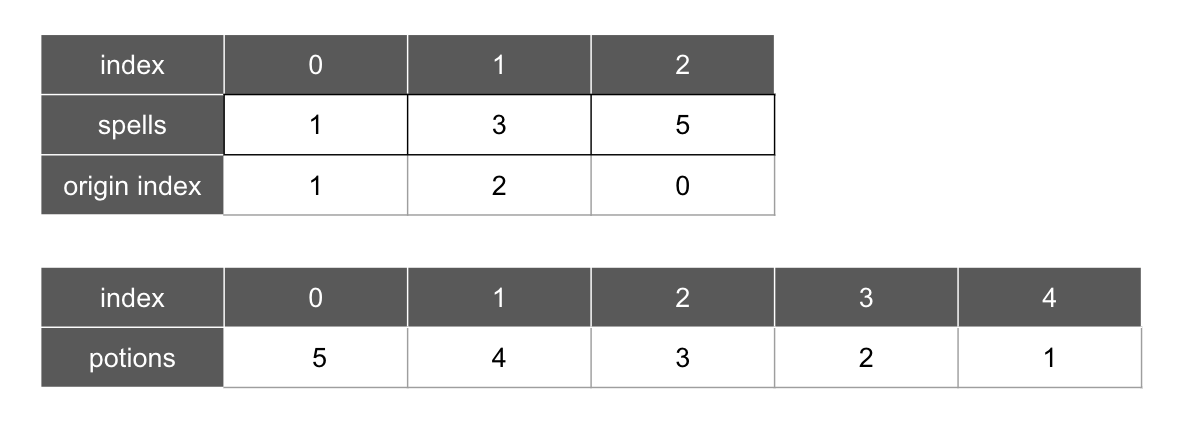
정렬하면 [그림 1]과 같아집니다.
spells의 origin index는 나중에 정답 배열을 만들 때 정답 배열의 갱신할 인덱스 입니다.
이제 spell * potion 연산 값과 success를 비교해갈텐데.
spell은 오름차순 정렬해놨기 때문에 작은 값부터 탐색해나가면 이후에 탐색하는 정답 pair 수는 이전보다 같거나 크게됩니다.
(spell[i-1] <= spell[i] 이기 때문)
potion은 큰 값부터 탐색해나갑니다. 그리고 현재 탐색 중인 spell 값으로 불가능한 가장 큰 지점을 찾아 탐색해나갑니다.
potion[i-1] >= potion[i] 이기 때문에 potion[i-1] * spell < success 이 불가능하다면 potion[i] * spell < success 또한 불가능하게 됩니다.
만약 다음 spell 을 탐색한다면 곱의 결과가 커지게 되므로 불가능했던 pair도 가능하게 될 수도 있기 때문에 탐색했던 인덱스를 다시 증가시키면서 갱신하면서 정답을 구합니다.
설명한 대로 [그림1]의 예제로 직접해보겠습니다.



불가능한 인덱스를 찾았으면 가능한 pair 수 또한 구할 수 있습니다.
탐색에 드는 시간은 O(N + M) 입니다.
시간복잡도는 정렬에 소요되는 시간인 O(NlogN + MlogM).
(코드의 potion 배열은 구현의 용이성 때문에 정렬은 오름차순 정렬 후 큰 값부터 탐색해갔습니다.)
'알고리즘 문제 > Leetcode' 카테고리의 다른 글
| [Leetcode] 2390. Removing Stars From a String (0) | 2023.04.11 |
|---|---|
| [Leetcode] 20. Valid Parentheses (0) | 2023.04.10 |
| [Leetcode] 881. Boats to Save People (0) | 2023.04.07 |
| [Leetcode] 1254. Number of Closed Islands (0) | 2023.04.06 |
| [Leetcode] 2439. Minimize Maximum of Array (0) | 2023.04.05 |




댓글